
In standard heuristic search, you need to find the optimal path from a starting state to a goal one; Because the path itself matters, it naturally,
-
defines the cost of every path.
-
stores the current optimal path and candidate optimal paths as it moves
However, if the optimal path is irrelevant and you only care about finding the optimal state, working with paths at all becomes unnecessary work.
…this is what Meta-heuristic search does.
What Meta-Heuristic Search is
It’s a search methodology that moves towards the optimal state by relying solely on the heuristic value of the current node it’s in.
Examples of Meta-Heuristic Search
I’ll compare them using a very simple, linear search space (where each state has exactly one parent and one child). This space consists of 100 states labeled 00 to 99, though I’ve only plotted some “key” states to reduce clutter.

Desc
(00 here is the identifier for the first state, it isn’t a numerical number)
Furthermore, I’ll use an even more condensed representation for the states, as a number line (to save space)

Each State has a heuristic value… and this is the heuristic value of each state:

Hill Climbing/Greedy Local Search (Local Search)
At each step, it evaluates its neighbors and blindly moves to the best-valued neighbor. It’ll keep moving up along the heuristic value curve until reaching the nearest peak and will NOT move again, even if there’s a higher top a few states ahead.

… In order for it to reach this maximum peak, it needs to take this very terrible path (according to them); Only then will it be able to charge into the peak.

However, it can never get itself to take this path, this is when Simulated Annealing comes in handy.
Simulated Annealing (Local Search)
It also only moves to the best-valued neighbor, but not always.
When it starts moving (t=0), it’s more likely to wander off to a worse neighbor (deliberately make a bad choice).
This makes it possible for it to take that terrible path to eventually reach the maximum peak.
Two column
Left
This is a code snippet that shows how it works.
Right
With desc

Local Beam Search (Population-Based Search)
It’s Hill Climbing but with multiple current solutions (not a single one.)
Basically, instead of making a single solution navigate the state space and move to the best one, k solutions are released simultaneously and they all generate their neighbors, the top k of which are kept, and this process keeps repeating.
It has a stochastic version that allows for choosing suboptimal neighbors, also to open/increase the chances to reach global maximums
Genetic Algorithms (Population-Based Search)
You also keep k solutions (the population), but the way this population changes is different.
The new population is formed by ranking solutions in the current population by their the fitness and doing the following k times: choosing 2 parents from this ranked list to crossover (combine) to create a solution.
This process should add k solutions to the new population; There’s also a chance that a solution gets mutated (this allows for having a more diverse population).
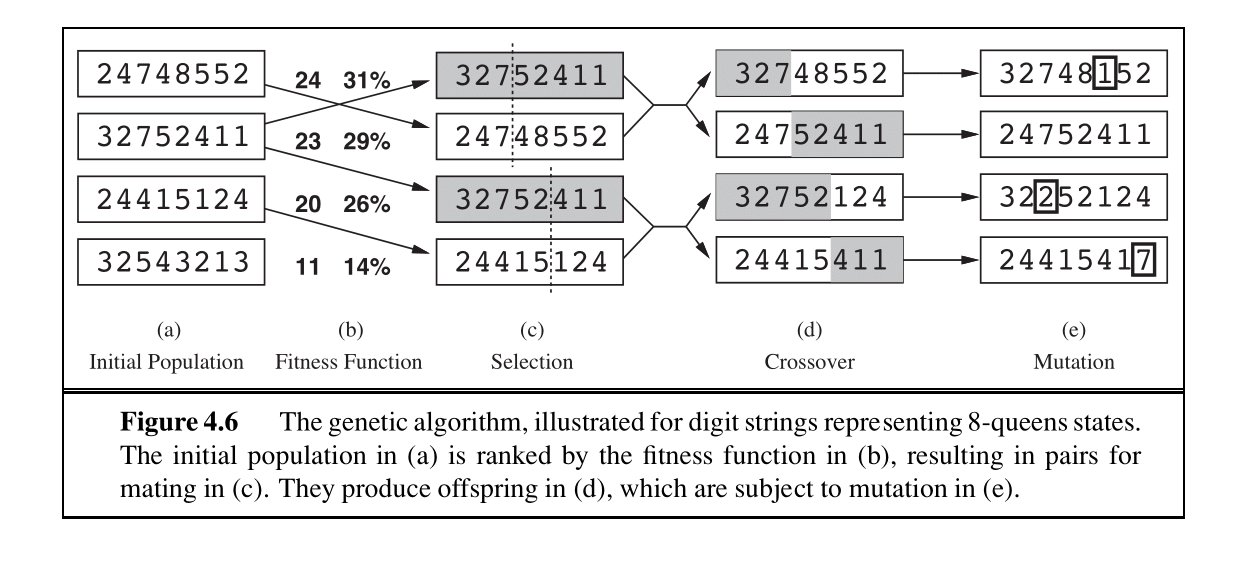
With desc
Desc
(Abualigah, L., Diabat, A. Advances in Sine Cosine Algorithm: A comprehensive survey. Artif Intell Rev 54, 2567–2608 (2021). https://doi.org/10.1007/s10462-020-09909-3)
Related Notes
| Thumbnail | Note |
|---|